API Reference¶
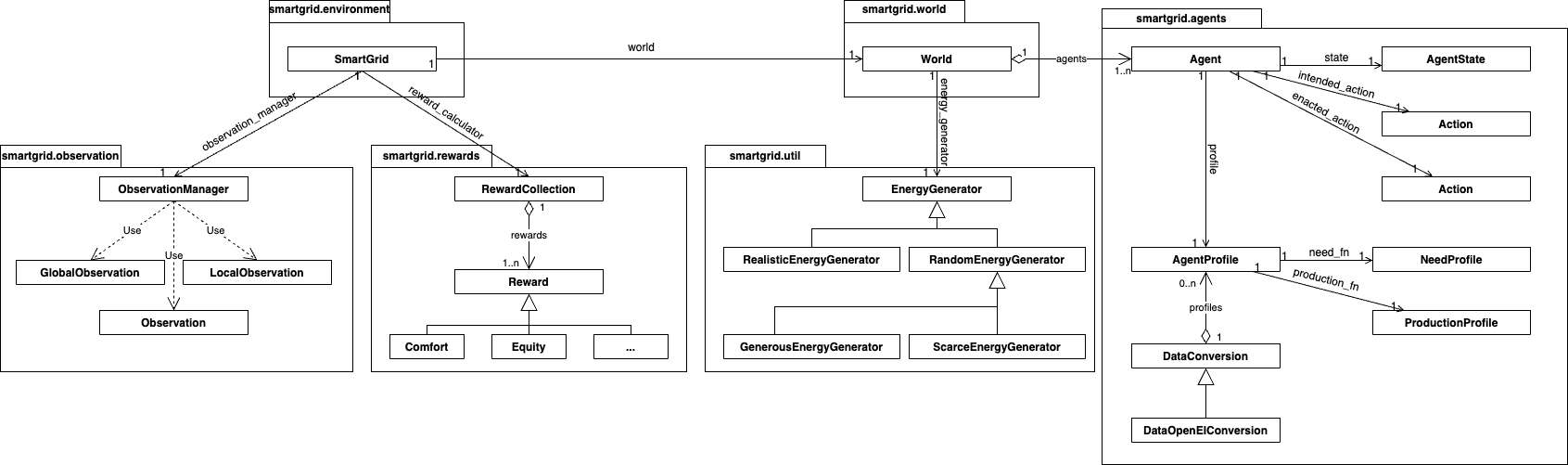
The smartgrid package defines the Smart Grid simulator. |
|
(Learning) algorithms that can be used to learn policies for agents. |
To facilitate the exploration of the API, the pre-defined components of interest are listed below, along with a short description.
Agents profiles and data conversion
comfortfunctions : describe how the agent’s comfort should be computed, based on the consumption and need.flexible_comfort_profile(): A comfort function that is easy to satisfy: the curve quickly increases.neutral_comfort_profile(): A comfort function that increases “normally”, the comfort follows more or less the ratioconsumption / need.strict_comfort_profile(): A comfort function that is difficult to satisfy: the consumption must be close to the need to see the comfort increase significantly.
Data Conversion: describe how to create anAgentProfilefrom raw data (dataset).DataOpenEIConversion: Creates profiles from the OpenEI dataset. Allows 3 kinds of buildings (Households, Offices, Schools) and 2 sources of needs (daily - aggregated and simplified, 24 data points ; annual - full dataset, 24*365 data points). Agent production is simulated (no available data).
World setup
Energy Generators: describe how much energy should be available each step, based on the agents’ total need at this step, minimal and maximal need.RandomEnergyGenerator: The “basic” energy generator, simply returns a random value based on the agents’ current total need. The bounds are configurable (e.g., between 80% and 120% of their current total need).ScarceEnergyGenerator: A random energy generator using 60% and 80% as bounds, i.e., there is never enough (100%) energy to satisfy all agents’ needs. This forces conflict situations between agents.GenerousEnergyGenerator: A random energy generator using 100% and 120% as bounds, i.e., there is always enough energy to satisfy all agents’ needs. This represents an easy scenario that can be combined with scarcity to see how agents perform after a change (e.g., how agents trained for scarcity perform during abundance, or conversely).RealisticEnergyGenerator: An energy generator that uses a dataset to determine how much energy is generated at each step. To ensure that it scales with the number of agents (and thus re-using datasets), this generator assumes that data correspond to percentages of agents’ maximum needs. This generator can be used to introduce time-varying dynamics, e.g., less energy in winter than in summer because of less solar power.
Reward functions
Numerical reward functions: Reward functions that are based on a “mathematical formula”, as is traditionally done in Reinforcement Learning.Difference Rewards: Reward functions that are based on comparing the actual environment with an hypothetical environment in which the agent did not act. This gives us an idea of the agent’s contribution.Equity: Focus on increasing the equity of inhabitants’ comforts.OverConsumption: Focus on reducing the over-consumption of agents, with respect to the quantity of available energy.MultiObjectiveSum: Focus on 2 objectives (increasing comfort, reducing over-consumption), and aggregates them with a simple sum.MultiObjectiveProduct: Focus on 2 objectives (increasing comfort, reducing over-consumption), and aggregates by multiplying them.AdaptabilityOne: Focus on 3 objectives (increasing equity when t<3000, then average of increasing comfort and reducing over-consumption). The reward function thus “changes” as time goes on, and the new considerations are completely different.AdaptabilityTwo: Focus on 2 objectives (increasing equity when t<2000, then average of increasing equity and reducing over-consumption). The reward function thus “changes” as time goes on, but simply adds a new consideration to the existing one.AdaptabilityThree: Focus on 3 objectives (increasing equity when t<2000, then average of increasing equity and reducing over-consumption when t<6000, then average of increasing equity, reducing over-consumption and increasing comfort). The reward function thus “changes” as time goes on, and adds several new considerations to the existing ones.
Per-agent Rewards: Reward functions that only consider the actual environment to compute the agent’s contribution. They have similar objectives as the Difference Rewards, but are particularly useful when the learning algorithm itself has a mechanism to determine agents’ contributions (e.g., COMA).Comfort: Focus on increasing the agent’s comfort. Can be used for self-interested agents, or in combination with other reward functions to create complex behaviours.
(Learning) algorithms
QSOM: the QSOM learning algorithm, based on the well-known Q-Learning and associated to 2 Self-Organizing Maps (SOMs) to handle multi-dimensional and continuous observations and actions.RandomModel: a naive algorithm that performs purely random actions. It is provided to easily check that the environment is working, without having to fine-tune a learning algorithm, and coding the random decision directly. It can also be used as a baseline to compare other algorithms with, although it is a very low baseline.